ランダムサーファーモデルとは?Googleの原点を世界一やさしく解説
ランダムサーファーモデルとは、Google検索の順位決定アルゴリズムの基礎となった「ウェブ上のリンクを人気投票と見なす」という考え方のことです。このモデルが、現在のSEOでも重要なPageRankの仕組みに繋がっています。
SEOを学び始めると、「PageRank」や「ランダムサーファーモデル」といった言葉に出会い、「なんだか難しそう…」「今さら古い理論を学んでも意味があるの?」と感じる方もいるかもしれません。
ですが、ご安心ください。このモデルこそがGoogle検索の原点であり、その考え方を理解することは、小手先のテクニックではないSEOの本質を掴む上で非常に大切なのです。
この記事では、Google創業者の論文などの一次情報源を参考に、ランダムサーファーモデルの仕組みから現代SEOとの繋がりまで、どこよりも分かりやすく解説します。
- ランダムサーファーモデルの基本的な考え方
- PageRankが計算される具体的な仕組み
- ランダムサーファーモデルの限界と、その後の進化
- 古い理論が現代のSEO戦略にどう生きているか
SEO内部リンク・サイト管理ツール
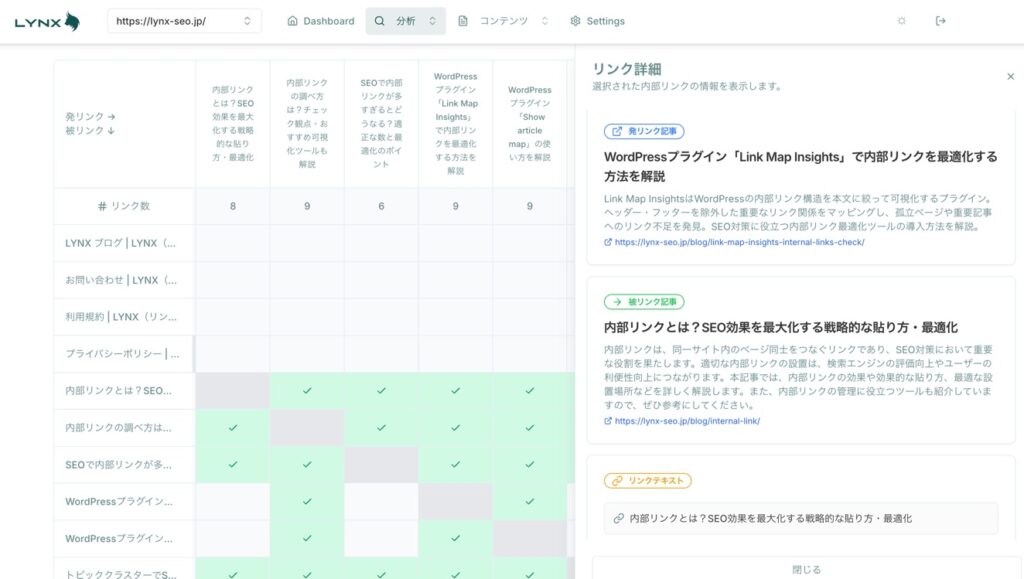
100ページ以上の記事情報や内部リンク、Excelでの管理はもう限界…
LYNX《リンクス》なら、複雑で大変な内部リンクやサイトの管理を効率化できます!
- 全ページのSEO情報を自動収集&一覧管理
- 内部リンク構造を「マトリクス表」で可視化
- トピッククラスターの設計&実装をサポート
現在β版の開発中!!
先行登録でβ版への優先アクセス権をプレゼント
ランダムサーファーモデルとは?Google検索の原点となった「人気投票」の考え方
このパートでは、ランダムサーファーモデルがどのような発想から生まれたのか、その基本的な考え方を紹介します。
Webの世界を「民主主義」に見立てた、Googleの独創的なアイデアの原点に触れていきましょう。
すべては「Webの民主主義」から始まった
1998年頃の検索エンジンは、主にページに含まれるキーワードの数で順位を決めていました。しかし、その方法では、ただキーワードを詰め込んだだけの中身のないページが上位に来てしまうという問題があったのです。
そんな中、当時スタンフォード大学の大学院生だったラリー・ペイジとセルゲイ・ブリン(後のGoogle創業者)は、ページ同士の「リンク関係」に目をつけました。彼らは、リンクをウェブページからの「支持表明」や「人気投票」のようなものと捉え、たくさんのページから支持されているページは価値が高い、と考えたわけです。
この「ウェブの民主主義」ともいえる画期的なアイデアが、後のPageRankアルゴリズム、そしてGoogleの飛躍的な成功の土台となりました。
参考情報:The Anatomy of a Large-Scale Hypertextual Web Search Engine
なぜ「ランダム」なのか?その単純さが持つ本当の意味
では、なぜ「ランダム(無作為)」などという、少し現実離れした仮定を置いたのでしょうか。
その理由は、ウェブという巨大すぎるネットワークを分析する上で、一人ひとりのユーザーの考えや気持ちを計算に入れるのは、事実上不可能だったからです。そこで、「ウェブを見ている人は、ページ上のリンクをどれも同じ確率で気まぐれにクリックする」という、非常に大胆でシンプルなルールを設けました。
不思議なことに、この大胆な単純化によって、かえってウェブ全体の構造的な本質、つまり「どのページに支持が集まっているか」という骨格がくっきりと浮かび上がってきたのです。
複雑な現実をシンプルに捉えることで本質を見抜く、ここにランダムサーファーモデルの面白さがあります。
つまりランダムサーファーモデルとは、ウェブ上のリンクを「人気投票」と見なす考え方です。ユーザーの行動をあえて「ランダム」と単純化することで、ウェブ全体のリンク構造からページの重要性を測るという、画期的なアイデアだったのです。
PageRankの仕組みを3ステップで理解【計算方法も解説】
このパートでは、ランダムサーファーモデルという考え方が、具体的にどのように「PageRank」という評価スコアに変わるのかを解説します。
この仕組みは、ページからページへと受け渡される評価、いわゆる「リンクジュース」という考え方の元にもなっています。3つのステップで、その仕組みを紐解いていきましょう。
Step1. リンクを辿る気まぐれなサーファーの誕生
まず、モデルの主役となる「ランダムサーファー」という架空の人物を想像してみてください。このサーファーは、ウェブ上をひたすら旅し続けますが、その行動には次のような単純なルールがあります。
今いるページにあるリンクの中から、どれか一つを完全にランダム(等確率)で選んでクリックし、次のページへ移動する。
もし、このようなサーファーがたくさんいれば、人気のページ(つまり、たくさんのリンクが集まるページ)には、自然と多くのサーファーが訪れるはずです。
 しば
しばこの「ページの訪れやすさ」を数値化したものが、PageRankの基本的な考え方になります。
Step2. 「飽き」をモデル化するダンピングファクター(0.85)
しかし、ウェブの世界にはリンクが一つもない「行き止まり」のページや、特定のページ同士でリンクがぐるぐる回っている「袋小路」のような場所もあります。もしサーファーがそういった場所に迷い込んでしまうと、二度と外に出てこられなくなるかもしれません。
そこで考え出されたのが、ダンピングファクター(減衰率)というルールです。これは、サーファーが時々リンクを辿るのに「飽きて」、全く別のページへ瞬間移動(ワープ)するという、少し変わった行動をモデルに加えるものです。
Googleの原論文では、このダンピングファクターは「0.85」に設定されました。つまり、サーファーは、
- 85%の確率で、ルール通りにリンクを辿る
- 15%の確率で、リンクを無視してウェブ上の全く別のページにランダムにジャンプする
この「飽き」というルールがあるおかげで、サーファーは特定の場所に閉じ込められることなく、Web全体を公平に旅し続けられるわけです。
参考情報:Method for node ranking in a linked database – Google Patents
Step3.【図解】小さなウェブサイトでPageRankを計算してみよう
では、実際に簡単なサイトを例に、PageRankがどのように決まるのか見てみましょう。
ここにA・B・Cの3ページだけのサイトがあります。
- ページAはBとCにリンクしています。
- ページBはCにリンクしています。
- ページCはAにリンクしています。
- 初期状態
全てのページが同じPageRank(1.0)を持っているとします。 - 1回目の計算
各ページは、自分のPageRankをリンク先に均等に分配します。- A(1.0) → Bへ0.5, Cへ0.5
- B(1.0) → Cへ1.0
- C(1.0) → Aへ1.0
- 各ページが受け取ったスコアは、A=1.0, B=0.5, C=1.5 となります。(※実際はダンピングファクターも考慮されますが、ここでは単純化しています)
- 2回目以降
この計算を何度も何度も繰り返します。すると、各ページのスコアは徐々に特定の数値に収束していきます。
最終的に、多くのページからリンクを受け、かつリンク元のページのスコアが高いページ(この例ではCやA)が、高いPageRankを持つことになります。
| 計算回数 | ページAのスコア | ページBのスコア | ページCのスコア |
|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 |
| 1 | 1.00 | 0.50 | 1.50 |
| 2 | 1.50 | 0.50 | 1.00 |
| … | … | … | … |
| 収束後 | 1.15 | 0.58 | 1.27 |
※数値はダンピングファクター0.85を考慮した概算値
このようにPageRankは、ランダムサーファーの行動を数学的にモデル化したものと言えます。各ページが持つ評価をリンク先に分配し、その計算を繰り返すことでウェブ全体のページの重要度を決定します。
その中でダンピングファクターは、計算をより現実的なものにするための重要な調整役を担っているのです。
ランダムサーファーモデルの限界と進化
これほど画期的なランダムサーファーモデルでしたが、もちろん完璧ではありません。その単純さゆえの、大きな弱点も2つありました。
このパートでは、その弱点と、それを乗り越えるためのアルゴリズムの進化について解説します。
弱点①:すべてのリンクを「平等」に扱いすぎた
ランダムサーファーモデルは、ページの中にあるリンクが、どれも同じ確率でクリックされると仮定していました。
しかし、現実のユーザー行動はもっと複雑です。例えば、記事の本文で紹介されているリンクと、ページの隅にある利用規約へのリンクでは、明らかに前者の方が注目され、クリックされやすいでしょう。
このように、リンクが置かれている場所による「重要度の違い」を無視して、すべてのリンクを平等に扱ってしまったのが、一つ目の弱点でした。
弱点②:悪意のあるスパムリンクに無力だった
もう一つの重大な弱点は、リンクの「質」を全く問わなかった点です。
その結果、「とにかく被リンクの数を集めれば順位が上がる」という考え方が広まり、質の低いサイトからのリンクを大量に売買したり、自動でリンクを生成したりする「スパム行為」が横行してしまいました。これが、SEOの歴史における「暗黒時代」の始まりです。
この2つの大きな弱点を乗り越えるため、Googleは次に「リーズナブルサーファーモデル」という、より現実的なモデルを開発することになります。
要するに、ランダムサーファーモデルはリンクの「場所」や「質」を考慮できなかったため、現実のユーザー行動との乖離やスパム行為に弱いという限界がありました。
この問題点を解決するために、Googleのアルゴリズムはさらなる進化を遂げていったのです。
【結論】現代SEOに生き続けるランダムサーファーの思想
「じゃあ、ランダムサーファーモデルはもう古い、役に立たない知識なの?」と感じるかもしれません。
ですが、そんなことはありません。その根底にある考え方は、形を変えながら現代のSEO戦略の土台として、今もしっかりと生き続けているのです。
教訓①:リンクは「数」より「重要な場所からの質」
PageRankの基本的な考え方は、たくさんのページから参照されること、そして「価値の高いページ」から参照されることが重要、というものでした。
これは、現代のSEOでよく言われる「権威性の高いサイトからの被リンクが重要」という考え方と、全く同じです。ランダムサーファーモデルは、その理論的な出発点だったと言えるでしょう。
教訓② サイトは「点」ではなく「線」で繋がっている
ランダムサーファーモデルが教えてくれる最も大切なことの一つは、ウェブサイトの価値はページ単体(点)で決まるのではなく、ページ同士の繋がり(線)によって作られる、という視点です。
この考え方を応用したものが、現代の内部リンク戦略に他なりません。また、関連する記事同士を密に繋いでサイト全体の専門性を高めるトピッククラスター戦略も、この「リンクによる価値の受け渡し」という考え方が土台になっています。
このように、ランダムサーファーモデルの「リンクで価値を渡す」という思想は、現代の被リンク評価や内部リンク戦略の基礎となっています。
しば古い理論だと切り捨てずに、その本質を理解することがとても重要です。
よくある質問
ランダムサーファーモデルは今も使われていますか?
いいえ、直接的には使われていません。しかし、その思想は「リンクによって価値が受け渡される」という、現代のGoogleアルゴリズムの最も基本的な部分として、今もなお生き続けています。
ダンピングファクターの「0.85」という数字に根拠はありますか?
Googleの原論文で示された経験的な値であり、数学的に絶対的な意味を持つものではありません。しかし、その後の多くの研究でもこの値が標準的に使われています。
自分のサイトのPageRankは確認できますか?
かつてはGoogleツールバーで公開されていましたが、2016年に完全に廃止されました。現在、Googleが内部で使う本当のPageRankを知ることはできません。ただし、Ahrefsの「DR」やMozの「DA」など、各SEOツールが独自の計算で出した類似の指標は参考にできます。
まとめ
今回は、Googleの検索アルゴリズムの原点であるランダムサーファーモデルについて解説しました。最後に、この記事の要点を振り返っておきましょう。
- ランダムサーファーモデルは、Web上のリンクを「人気投票」と見なす、Googleの基本的な考え方です。
- PageRankは、このモデルを基に、各ページが持つ評価をリンク先に分配し、それを繰り返すことで計算されます。
- この「リンクで価値を渡す」という思想は、現代のSEOで重要視される「権威性」や「内部リンク戦略」の基礎となっています。
ランダムサーファーモデルの考え方をもとにしている
SEO内部リンク・サイト管理ツール
100ページ以上の記事情報や内部リンク、Excelでの管理はもう限界…
LYNX《リンクス》なら、複雑で大変な内部リンクやサイトの管理を効率化できます!
- 全ページのSEO情報を自動収集&一覧管理
- 内部リンク構造を「マトリクス表」で可視化
- トピッククラスターの設計&実装をサポート
現在β版の開発中!!
先行登録でβ版への優先アクセス権をプレゼント
